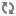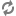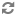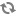-
InfoHub Configuration File
An InfoHub Configuration File contains line entries for descriptors that configure an InfoHub. Each descriptor starts with a case-insensitive keyword that defines a type. Descriptors also typically contain Names and IDs. A Name is case-sensitive and must start with an alphabetic character; it can contain up to 32 alpha-numeric characters. An ID is a 31 bit positive integer.
-
InfoHub Descriptor
An InfoHub descriptor is generally the first non-comment line of an InfoHub Configuration File. It establishes the ID and/or Name of the InfoHub to which the Configuration File applies.
Especially in a world of cloud-based computing, systems are ephemeral, but data gleaned from monitoring them often has long-term value and will require storage beyond the lifetime of individual systems. As the InfoHubID is the first level key used to store information in an InfoHub database. Giving each InfoHub a distinct key simplifies merging data from multiple InfoHubs into a database without changing first level keys. If ID is unspecified for a new InfoHubName, InfoHub assigns a random ID at creation time. FIS recommends using a random ID for each new InfoHub.
The syntax of an InfoHub Descriptor is:
InfoHub:[InfoHubName][:InfoHubID]
-
InfoDict Descriptor
The InfoHub InfoDict is an information dictionary for data stored in an InfoHub. InfoDict Descriptors describe the relationships between InfoHub components. There are two types of InfoDict Descriptors a?? InfoDict Domain and InfoDict Item. An InfoDict Domain has a Descriptor called InfoDict and groups a category of components into a name space. An InfoDict Domain can have multiple parent Domains and can also be the parent of multiple child Domains.
An InfoDict Item has a Descriptor called InfoDictItem. An InfoDict Item is a named object within an InfoDict Domain. By default, every Item in an InfoDict Domain has a path to all the Items in any Domain that name it as a parent. If a domain has a parent that contains an item with an ID and Name that match its own ID and Name, only the matching item in the parent domain has a path to the items in the child domain. For example, if a domain D contains items A, B and X, and a second domain C names D as a parent and contains items J and K, the configuration has paths A->J, A->K, B->J, B->K, X->J and X->K; if there is a third domain X with an ID that matches the ID of the X item in D, names D as a parent and contains items P and Q the configuration also has paths X->P and X->Q.
In the following illustration, gray and light blue boxes represent InfoDict Items and the rest represent InfoDict Domains. You associate InfoDict Items with an element or a collection of elements you want to monitor. You typically create an InfoHub framework by associating InfoHub components including Publishers, PipeLine Processors, FileLine Processors, and Subscriptions with InfoDict Domains and Items. The association of InfoDict Domains/Items with InfoHub components/monitoring elements is a matter of configuration and conventions in your organization. The following example shows:
An InfoHub called Simple Monitor.
InfoDict Items with msg, Days, Load01, Load05, and Load15 to describe monitored information.
A Publisher with System to mange information gathering.
A PipeLine processor with UpTime to monitor process output (Days, Load01, Load05, and Load15) of the uptime command.
FileLine processors called AuthLog and OpLog to monitor messages (msg) in authentication log (/var/log/auth.log) and system log (/var/log/messages).
Subscriptions called GTMErr, AuthFail, PatchMe, and DontBeLazy each to watch a specified condition and send notifications to Subscribers. For example, a condition such as msg["Fail" could help Monitoring Management determine the occurrence of a failed login attempt.
A Reporting Adaptor with Monitoring Management that uses the GTMErr, AuthFail, PatchMe, and DontBeLazy Subscriptions and also, on request, gathers other data from System Monitor to report information. Additionally, the diagram shows Monitoring Management as a reporting adaptor that interfaces with other Monitors, using other components in the same InfoHub or other InfoHubs, and their Subscriptions to aggregate information across multiple systems.
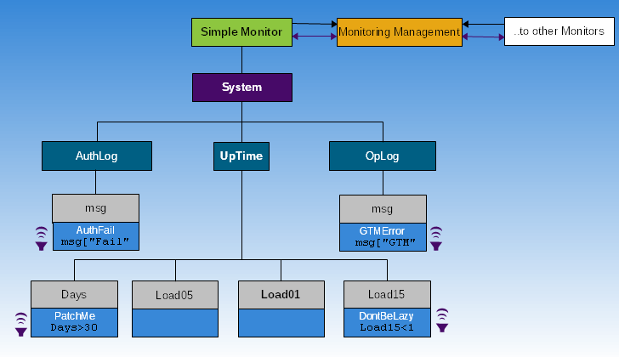
The bold text starting from Simple Monitor towards System up to Load01 denotes one Path.
This illustration is conceptual and merely describes at a high-level how InfoHub uses InfoDicts. In the real world, you would create InfoDict hierarchy and Paths according to your monitoring requirements, your conventions, and nuances of the business processes in your organization.
The syntax of an InfoDict Domain Descriptor is:
InfoDict:InfoDictName:[InfoDictID][:{ParentInfoDictID | ParentInfoDictName}]The syntax of an InfoDict Item Descriptor is:
InfoDictItem:{InfoDictID | InfoDictName}:ItemName:[InfoDictItemID]:[Label]:[Type][:ItemDescription]-
Publisher Descriptor
Manages the FileLine and PipeLine processes gathering information for a particular environment.
The syntax of an Env Descriptor is:
Publisher:Publisher:{InfoDictID|InfoDictName}:[PublisherName]:[PublisherID]:[APIDir]:[TempPWD]:[TempDBAlloc]:[TempDBExtend]-
Env Descriptor
Manages the environment provided to information gathering processes. Depending on its position in the configuration file, an Env descriptor can be associated with the InfoHub itself (that is, common to all Publishers), or it can be associated with a specific Publisher, which applies it to any PipeLine processing for that Publisher.
The syntax of an Env Descriptor is:
Env:EnvVarName[=[Value]][,,,,]
-
FileLine Descriptor
A FileLine descriptor defines the monitoring of a text file. The Publisher master process JOBs a FileLine process which reads the monitored file, line by line, executing a GT.M extrinsic function invocation for each line read to gather per-line information. The FileLine process waits for and reads lines from the monitored file (behavior equivalent to a tail -f). The InfoDict Descriptor illustration associates OpLog and AuthLog each with a FileLine.
The syntax of a FileLine Descriptor is:
FileLine:{InfoDictID | InfoDictName}:FileLineName:[FileLineID]:{PublisherID | PublisherName}:/path/to/Filename:[CheckCycle]:[Timeout]:[PieceSeparator]:[PreExpr]:[InfoExpr]:[PostExpr]-
PipeLine Descriptor
A PipeLine Descriptor defines the aspects of monitoring output from a process. The monitored process can be a GT.M (any version) process or any other UNIX process. The Publisher master process JOBs a PipeLine process which OPENs a PIPE device using the configured command and READs its stdout and/or stderr line by line, feeding each one to the gleaner extrinsic function configured as InfoExpr. The InfoExpr gleaner sub-routine performs any processing of the raw input from the PIPE into zero or more key:value pairs ready for filing by the PipeLine process in the InfoHub database. The PipeLine can also be configured with a PreExpr and/or a PostExpr. The InfoDict illustration associates the InfoDict Name UpTime with a PipeLine.
The syntax of a PipeLine Descriptor is:
PipeLine:{InfoDictID | InfoDictName}:PipeLineName:[PipeLineID]:{PublisherID | PublisherName}:PipeCmd:[PipeCycle]:[Timeout]:[PieceSeparator]:[PreExpr]:[InfoExpr]:[PostExpr]-
xLine Gleaner
An xLine Gleaner implements the PreExpr (optional), InfoExpr and PostExpr (optional) used in the FileLine and PipeLine. The gleaner performs any processing of each raw input line from the file into zero or more key:value pairs ready for filing by the xLine process in the InfoHub database. The xLine process checks each key returned by the gleaner extrinsic function to see that it's configured, and files it if it is or discards it if it isn't. The xLine can also be configured to invoke a PreExpr, that might perform any appropriate initialization when it first starts and a PostExpr that might provide summary information when it shuts down. PreExpr and PostExpr can return zero or more key:value pairs to the xLine base routine. Typically, you use a FileLine Gleaner for active monitoring of a text file and a PipeLine Gleaner for any formatting of information returned by the PIPE coprocess.
-
Include Descriptor
An Include Descriptor specifies a file that contains additional descriptors, and permits different organizations of descriptors, such as by type or target environment.
The syntax of an Include Descriptor is:
Inc:Include:FilePathSpecification
-
Subscriber Descriptor
The InfoHub alerts a Subscriber when a configured condition occurs. A Subscriber can monitor multiple Subscriptions. In the InfoDict illustration, an example for a Subscriber is Monitoring Management which gets alerted when a configured condition such as msg["Fail" occurs. Subscribers provide reactive and passive monitoring where there is a need to react when a Subscription condition occurs.
The syntax of a Subscriber Descriptor is:
Subscriber:{InfoDictID | InfoDictName}:[SubscriberName]:[SubscriberID]For more information, see "Reporting Adaptor".
-
Subscription Descriptor
A Subscription watches for a condition in an InfoDict Item to send alerts to its Subscribers. The condition is specified using a GT.M binary operator (excluding concatenation and non-relational arithmetic operators) or the (case-insensitive) text "NoInfo". The GT.M binary operator condition can be used to establish several monitoring conditions including setting thresholds, detecting changes in the value of the InfoDict item, and so on. A Subscription can have multiple Subscribers and also apply to multiple Publishers.
"Noinfo" detects a period during which the specified InfoDict Item receives no new data. It is used for monitoring the lack of activity on an InfoDict Item. The InfoDict illustrations associate PatchMe, DontbeLazy, GTMError, and AuthFail with a Subscription because they watch a specified condition (for example, Load15<1).
The syntax of a Subscription Descriptor is:
Subscription:{InfoDictID | InfoDictName}:SubscriptionName:[SubscriptionID]:{InfoDictID | InfoDictName}:{InfoDictItemID | InfoDictItemName}:Condition:[Value]:[Period]:[entryref]:[SubscriberID,...]:[PublisherID,...]-
Reporting Adaptor
A Reporting Adaptor generates reports from the data gathered in InfoHub. A Reporting Adaptor is not a part of the InfoHub core product. The relationship between an InfoHub and an Adaptor is of two types a?? Subscriber and Query. A Reporting Adaptor has a Subscriber relationship when it registers with an InfoHub to receive alerts from Subscriptions. A Reporting Adaptor has a Query relationship with InfoHub when it looks at data at its own initiative. A Reporting Adaptor may have a Subscriber, Query, or Subscriber and Query relationship with an InfoHub. These relationships are described in the Overview section. The InfoHub Reference Implementation includes a ready-to-use SNMP Reporting Adaptor for sending aggregated data using an SNMP sub-agent via the Internet standard AgentX protocol (RFC 2741) for report presentation. The InfoDict illustration, Monitoring Management, uses a Reporting Adaptor. You can use a Reporting Adaptor for both proactive monitoring, to access data from InfoHub, as well as for reactive monitoring, in response to an alert to a Subscriber from InfoHub. Although a Subscribers must be registered with InfoHub, proactive monitoring can be transparent to InfoHub.
The syntax of a Subscriber Descriptor is:
Subscriber:{InfoDictID | InfoDictName}:[SubscriberName]:[SubscriberID]-
Configuration Processing
An InfoHub Configuration File must cover all existing configuration to be retained or modified as well as any new configuration. Configuration processing disables any preexisting item(s) omitted by a new file, but does not purge its configuration (or its related data). You can purge information in the InfoHub that is older than a specified time.
The following aspects are common to all InfoHub Configuration Files:
InfoHub configuration files are descriptive, line-oriented, ASCII or UTF-8 text files. If you use UTF-8 characters outside the ASCII subset in the configuration files, InfoHub itself must run in UTF-8 mode.
Leading and trailing whitespace (tab or space) is ignored.
Lines starting with two forward slashes ("//"), as well as blank lines, are comment lines.
Names (such as a PublisherName) start with an alphabetic character, followed by zero to 31 ASCII alphanumeric characters. Except where otherwise explicitly stated, InfoHub uses case-sensitive Names. Attempting to use a Name that does not meet these parameters produces an IHBADNAME error.
IDs (such as a PublisherID) are positive (non-zero) canonical GT.M integers; attempting to use zero (0) for an ID produces an IHZEROIDINVALID error; attempting to use a non-integer or out-of-range ID produces an IHIDINVALID error. Configuration processing supplies IDs for items specified by Name, but without an ID. Allowing the configuration processing to generate random IDs for items such as Publishers makes it easier to move existing information between InfoHub databases with almost no likelihood of conflict. You should make an explicit choice of ID under the following circumstances:
Attempting to configure a descriptor with an unrecognized type produces an IHBADDESCTYPE error.
Reading the same Configuration File repeatedly is a no-op.
While the first colon (:) is frequently required, other trailing colon delimiters are optional, although for simplicity the descriptor syntax definitions technically appear to require them. Attempting to configure a descriptor with too many colon (:) delimiters produces an IHEXTRADELIM error - this attempts to guard against inadvertent use of embedded delimiters.
Fields shown as optional may not be optional under all conditions - for example: while both Name and ID may be optional, typically you must supply at least one of them, and, for a pattern match (?) or NoInfo condition, Value is not required (actually not accepted), for other conditions, it is required.
The InfoHub process parses and applies the Configuration File. The presence of even one error in the Configuration File or any associated Include files prevents the configuration process from loading its specifications at all and from recording their contents. In order to facilitate rapid debugging of Configuration files, the configuration process attempts to continue processing after it detects most errors, which can produce ancillary or duplicate errors. The configuration process records the fact that it read and either accepted or rejected the Configuration File.